Learning from Simulated and Unsupervised Images through Adversarial Training by Ashish Shrivastava et al. is published in 2016 which introduced a new method which transforms synthetic images to look real in order to use in adverarial training. This paper led various models to reach SOTA by only transforming input images which is fed to those models.
https://arxiv.org/abs/1612.07828
Learning from Simulated and Unsupervised Images through Adversarial Training
With recent progress in graphics, it has become more tractable to train models on synthetic images, potentially avoiding the need for expensive annotations. However, learning from synthetic images may not achieve the desired performance due to a gap betwee
arxiv.org
Synthetic Images
Machine Learning systems' performance strongly depend on the quality and quantity of training dataset. As labeled data is precious, there were attempts to utilize synthetic images on training. However, those images lack realism as compared to other real images, and the model overfitted into the details of spurious artifacts.
Simulated + Unsupervised(S+U) Learning

This paper introduces the S+U(Simulated and Unsupervised) model in order to improve the realism of synthetic images which is generated by a simulator. It is astonishing that to train this Refiner model, we only need unlabeled data. For other models to use images refined with S+U as their input, it is crucial to preserve the annotation and prevent artifacts while refining.
Preserving Annotations
Annotations are the supplemental features which original images include, which may be important when those images are used as a training dataset. For example, lets assume that we have simulated and generated various images of dogs and cats which have various colors. If we trained this images for classifying dogs and cats, then their colors would be not that important. However, if we use those images for classifying breeds, then color would be a crucial feature. As we can see, annotations are subjective to the objective of the model which the data is trained on, and refiners should preserve these annotations as much as possible.
Preventing Artifacts
Artifacts are features or part of an generated image which looks too heterogeneous compared to real images. These artifacts can lead models trained on those images to overfit on those unique features(artifacts) and work poorly on testing data(real images).

S+U with SimGAN
In order to train S+U to correctly refine images with unlabeled images, we need to design an adversarial network model which is named SimGAN by the paper.
Defining Loss Function
We first need to establish the loss function which is going to be used at the Refiner and the Discriminator.
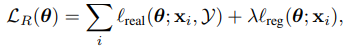
$\ell_{real}$ comes from how much the refined image looks real, and $\ell_{reg}$ comes from how refined image preserves its annotation. We'll break those losses in detail in breif.
Enhance Realism
If the refined image looks real, then it means that the distribution of the refined and real images are similar. To achieve this, we'll train a discriminator in order to push the refiner to generate more realistic images. Then the loss of discriminator would be like below.

The loss resembles a cross-entrophy error for two classes, in this case being synthetic or real. $D_\phi$ is the probability of the input being synthetic, in terms of the model's parameter $\phi$. $\tilde{x_i}$ is the refined image of $x_i$ and $y_i$ is the unlabeled real image. The discriminator is structured as a convolutional network.
The realism loss $\ell_{real}$ comes from this discriminator which is as followed.

Self-Regularization
While the refiner transforms the synthetic images to look real, preserving its annotation is equally important. This could be applied to the loss function as a self-regularization term $\ell_{reg}$.

However, if there exists a significant distance or difference from synthetic images and real image, then we could insert a simple transform function inside the self-regularization term. In the case of paper, the researchers used the mean of color channels to produce refined images which is more realistic.

Training
We can train both losses of discriminator and refiner by minimizing $\mathcal L_R(\theta)$ and $\mathcal L_D(\phi)$ alternately, with fixing the other loss's parameters. The overall training algorithm is like below.

Local Adversarial Loss
If we train the refiner model to generate images with the loss only regarding to full image, then the refiner would try to compensate some feature's miss by twicking other feature severely, which could lead an artifact to appear on certain spot of the generated image. In order to remove these artifacts which appear locally, we need to break down full image into several spots and compute each spots probability respectively. As each local spots(patches) should have similar statistics among the patches of the real images, this method would prevent local artifacts effectively.
In the implementation, discriminator produces $w \times h$ outputs which corresponds to the number of local patches and its cross-entropy loss is summed to be used at training.
History of Refined Images
If we train the discriminator and the refiner in real-time, the discriminator can easily forget images from pass, while concentrating only on current images. This could lead the refiner to easily fake the discriminator while not learning the overall features well. This problem could be handled by using a history of refined images, and reselecting those images to fill some portion of the batch. This would lead the discriminator to keep remember the images once fed and maintain stable training.
Experiments
SimGAN were applied to many tasks involving synthetic images as their training data. Preserving the annotation while refining, which is the main advantage of SimGAN, makes it able to be applied to various areas. The paper introduces two main tasks which is gaze estimation, and Hand Pose estimation. Both tasks include images which is simulated by programs like Unity, and fed to the model directly. By training SimGAN to refine simulated images to look real, overall performance was incredibly enhanced.
Ablation studies
Ablation study means finding out how much each important features effect the overall result. In this case, we'll breifly analize two feature, which is using history of refined images, and using local adversarial loss.
History of Images
As we can see on the comparable images, the usage of history makes refined image produce less unrealistic artifacts, which means that the model has learned realistic features.

Local adversarial Loss
Using local adversarial loss compared to the global loss creates images which have smoother edges and less noise. This leads the SimGAN to generate more realistic image.

'Research Analysis > Data Science' 카테고리의 다른 글
| HINet : Half Instance Normalization Network for Image Restoration (0) | 2021.09.05 |
|---|---|
| CycleGAN : Unpaired Image-to-Image Translation - Research Analysis (0) | 2021.08.19 |
| Batch Normalization - Research Analysis (0) | 2021.08.18 |
| YOLO9000: Better, Faster, Stronger - Research Analysis (0) | 2021.08.01 |
| You Only Look Once: Unified, Real-Time Object Detection - research analysis (0) | 2021.07.28 |